
[LLM] PEFT 기법 - LoRA와 qLoRA
Open Source LLM의 민주화를 연 파인튜닝 기법인 LoRA와 QLoRA 기법에 대해서 알아봅니다.
원제 LoRA: Low-Rank Adaptation of Large Language Models
QLoRA: Efficient Finetuning of Quantized LLMs
본 포스트는 LoRA와 QLoRA 논문을 리뷰한 내용과 huggingface transformers를 사용해 파인튜닝 하는 내용에 대한 설명을 포함하고 있습니다.
원문은 여기에서 보실 수 있습니다.
LoRA paper,QLoRA paper
Contents
- Intro - 이 많은 파라미터를 굳이 다 학습해야하나?
- LoRA: 저차원으로 압축해보자!
- QLoRA: 양자화된 모델에 LoRA 태우기
- Fine-Tuning 실습: Huggingface API 활용
1. Intro - 이 많은 파라미터를 굳이 다 학습해야하나?
언어 모델의 크기가 성능에 비례한다는 실험적 결과가 점차 누적되면서 (LLM Scaling laws) LLM의 사이즈는 꾸준히 증가해 왔습니다.
그러던 중 Meta의 LLAMA를 필두로 다양한 size의 LLM들이 open source로 공개되고 있는데요.
지금에 와서(2023년 10월) 우리가 마주하게 된 open source LLM 모델의 파라미터 수는 적게는 7B, 많게는 180B에 이르게 되었습니다.
그런데 그림의 떡이라고 할까요, 막상 공개되어도 우리같은 가난한 영세 개발자들은 써 볼 수가 없습니다.
4080 한장 구하면 감사합니다 하는 와중에 80GB, 320GB VRAM을 얻어야만 모델을 학습할 수 있다니 애초에 가능한 선택지 같지 않을텐데요.
이러한 상황에서 조금 더 효율적으로 모델을 파인튜닝 해보자! 하고 제안된 것이 PEFT 기법입니다.
PEFT는 말 그대로 Parameter Efficient Fine-Tuning의 약자로, 소수의 파라미터로 원하는 Task를 학습시키는 전략입니다.
이 많은 파라미터를 굳이 다 학습해야해? 라는 단순한 아이디어에서 시작된 참신한 해결책이라고 할 수 있겠습니다.
한편 이와 다르게 Memory Efficient한 방식으로 Fine Tuning을 수행하는 기법도 연구되고 있습니다.
2. LoRA: 저차원으로 압축해보자!
오늘 이야기 할 LoRA는 대형 언어 모델(LLM)을 파인튜닝할 때, 전체 파라미터를 파인튜닝 (Full Fine-tuning) 하는 대신 소수의 추가적인 파라미터만을 업데이트하여 효율적으로 파인튜닝하는 기법입니다.
이 기법은 pretrained된 모델의 weight를 고정(freeze)하고, 이 큰 pretrained weight를 저 랭크(Low Rank)를 갖는 두 개의 행렬을 사용해 간접적으로 최적화하는 아이디어에 기반합니다.
논문에서는 135B의 파라미터를 가진 원본 12,888차원의 정보를 1,2차원의 저차원에서 표현이 가능하다는 것이 실험을 통해 확인했다고 주장합니다. 이를 통해 파인튜닝에 필요한 시간과 공간 복잡도를 크게 줄일 수 있습니다.
이 기법은 학습에 필요한 파라미터의 수를 0.01% 수준까지 줄이면서도 성능을 보존할 수 있어 혁신적입니다.
GPT-3 모델을 학습할 때 필요한 메모리 량을 1.2TB에서 350GB 수준으로 줄일 수 있다고 합니다.
그 외에도 이 rank를 줄일수록 큰 압축이 가능한데, rank=4로 설정한 Transformer 모델의 경우 350GB 소요량을 35MB로 10,000배 압축할 수 있다고 하네요.
LoRA의 장점
이어서 LoRA가 왜 좋은지 알아보겠습니다.
1) Memory Efficiency
-
LoRA Adapter를 사용함으로써, GPU 메모리를 효율적으로 활용하여 Fine-tuning에 필요한 GPU 메모리 필요량을 줄일 수 있음
-
Full Fine-tuning의 경우, LLM 모델 자체의 파라미터 외에도 gradient 및 학습 관련 정보를 GPU에 로드해야 하므로 GPU 메모리가 크게 필요함
-
반면, LoRA는 본 모델에 비해 더 작은 일부 LoRA 파라미터와 관련된 기울기 값만을 보존하므로 메모리가 효율적으로 사용됨
2) Full Fine-tuning의 일반화
- low rank 파라미터인 r의 값을 키워감에 따라, 기존의 모델을 근사화하는 것과 유사하다고 볼 수 있음
- 적은 수의 파라미터로 전체 모델을 근사화하는 것이 가능 -> 원본 모델의 정보를 denoise하여 잘 녹여낼 수 있는 구조를 가짐
- 이는 Matrix Factorization과 Dimensionality Reduction 기법의 아이디어와 유사하다고 볼 수 있음
3) No Additional Inference Latency
- 다른 Downstream Task를 수행하고 싶다고 할 때, 새로운 LoRA 모델만을 학습하여 이들을 활용하면 됨
- 즉, 다양한 task를 번갈아가면서 수행할 때 발생하는 지연이 매우 적음 (no additional inference latency)
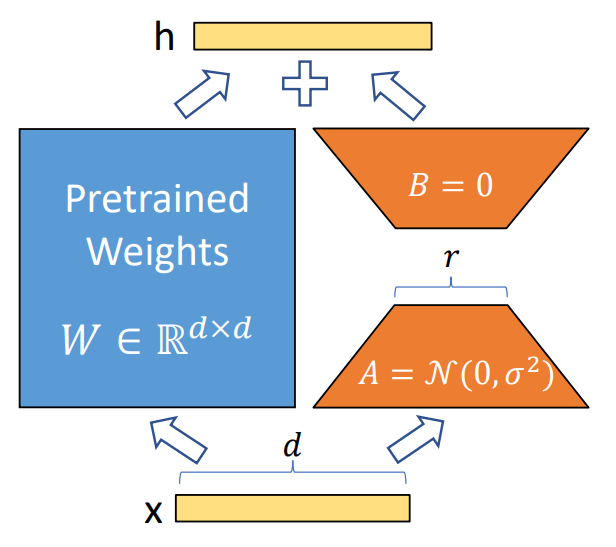
Low-Rank-Parameterized Update Matrices
$h = W_0x + \Delta Wx = W_0 + BAx$
해당 수식은 맨 초반 부분의 논문 그림 자료를 그대로 수식화한 것인데요, 그 풀이는 아래와 같습니다.
- 다음 레이어에서의 hidden state인 $h$는
- 이전 레이어에서의 input tensor인 x를 각각
- Freeze된 pretrained weight matrix인 W_0과 $\Delta W$에 각각 곱해준 것의 합과 같은데,
- $\Delta W$는 Low Rank Matrix인 $A$와 $B$를 순차적으로 곱해준 것과 동일하다
이를 좀 더 들여다 보기 위해, 실제 peft 라이브러리를 적용해 생성한 LoRA 장착 모델의 구조를 살펴보겠습니다.
예시 코드
아래는peft라이브러리를 활용해 베이스 모델에 LoRA를 붙이고, 만들어진 구조를 살펴보는 간단 예시입니다.
!pip install transformers peft accelerate bitsandbytes
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
from peft import LoraConfig, get_peft_model, PeftModel, PeftModelForCausalLM, PeftConfig
base_model_name = "EleutherAI/gpt-neo-1.3B"
tokenizer = AutoTokenizer.from_pretrained(base_model_name)
model = AutoModelForCausalLM.from_pretrained(
base_model_name,
device_map="auto",
torch_dtype=torch.float16
)
# LoRA Config 설정
lora_config = LoraConfig(
r=4,
lora_alpha=16,
target_modules=["query_key_value"], # 예시: GPT-Neo 구조상 주로 QKV에 적용
lora_dropout=0.05,
bias="none",
task_type="CAUSAL_LM",
)
# LoRA 모델 생성
lora_model = get_peft_model(model, lora_config)
# 모델 구조 출력
print(lora_model)
# 몇 개의 파라미터가 학습 가능한지 출력 (참고용)
def print_trainable_parameters(model):
trainable = 0
total = 0
for _, param in model.named_parameters():
total += param.numel()
if param.requires_grad:
trainable += param.numel()
print(f"Trainable params: {trainable} / {total} = {100 * trainable/total:.2f}%")
print_trainable_parameters(lora_model)
이 코드 실행 결과를 보면, LoRA가 장착된 모듈들을 확인할 수 있고, 실제로 학습 가능한(gradient가 업데이트되는) 파라미터가 매우 적어졌음을 알 수 있습니다.
LoRA in Detail
LoRA를 조금 더 자세히 들여다보겠습니다. 이 글을 보시는 분들은 모두 아시다시피, 모든 뉴럴넷은 행렬 연산을 포함합니다.
저자들은 선행 연구에서 주장하듯이 파인튜닝 과정에서 중요 정보를 포함하는 내재 차원(intrinsic dimensionality)이 있을 것이라고 예상하며, 이 점에서 착안하여 더 파라미터 효율적으로 원 행렬의 정보를 adaptation할 수 있을 것이라는 가설을 세웠습니다.
여기서 Adaptation이란, pretrained 모델이 가지고 있는 지식을 downstream task에 활용할 수 있도록 녹여내는 과정을 의미합니다.
LoRA in Detail
LoRA를 조금 더 자세히 들여다보겠습니다. 이 글을 보시는 분들은 모두 아시다시피, 모든 뉴럴넷은 행렬 연산을 포함합니다.
저자들은 선행 연구에서 주장하듯이 파인튜닝 과정에서 중요 정보를 포함하는 내재 차원(intrinsic dimensionality) 이 존재한다고 가정했으며, 이러한 내재 차원을 효율적으로 활용하면 원 행렬의 정보를 적은 파라미터로도 잘 adaptation할 수 있을 것이라고 봤습니다.
여기서 Adaptation이란, pretrained 모델이 가지고 있는 지식을 downstream task에 활용할 수 있도록 녹여내는 과정을 의미합니다.
이를 auto-encoder처럼 복원해내는 두 개의 low-rank 행렬 $A$와 $B$를 도입합니다.
\[A \quad \in \quad \mathbb{R}^{r \times k}, \quad B \quad \in \quad \mathbb{R}^{d \times r}\]즉, $W_0$를 freeze한 상태에서 $A$와 $B$의 파라미터만 업데이트함으로써, 효율적으로 학습을 진행하게 됩니다.
LoRA의 학습 과정
여기서 핵심 아이디어가 등장합니다.
$W0$를 freeze하고, $A$와 $B$의 파라미터만을 업데이트한다고 말씀드렸는데요. 이 때, downstream task를 수행하기 위해 loss function을 최적화해 나가며 역전파 하는 과정을 주목할 만 합니다.
나이브하게 말하자면, 문제를 해결하기 위해 필요한 $W_0$의 방대한 정보 중 필요한 핵심 지식이 $A$와 $B$에 녹아들게 되는 셈입니다.
중요한 점은 첫 순전파 & 역전파 과정이 이루어질 때 random generate된 weight에서 생성된 정보가 노이즈로 작용하지 않도록 $B$의 파라미터를 0으로 초기화한다는 것입니다. 이러한 조치를 통해, 첫번째 순전파 시 LoRA 레이어의 정보가 전혀 전달되지 않습니다.
이러한 과정을 통해 첫 번째 역전파부터 파라미터가 업데이트 됨으로써 adaptation이 일어나게 됩니다. (adaptation을 수행하는 주체인 LoRA 모델을 Adapter라 부르는 이유이기도 합니다.)
3. QLoRA: 양자화된 모델에 LoRA 태우기
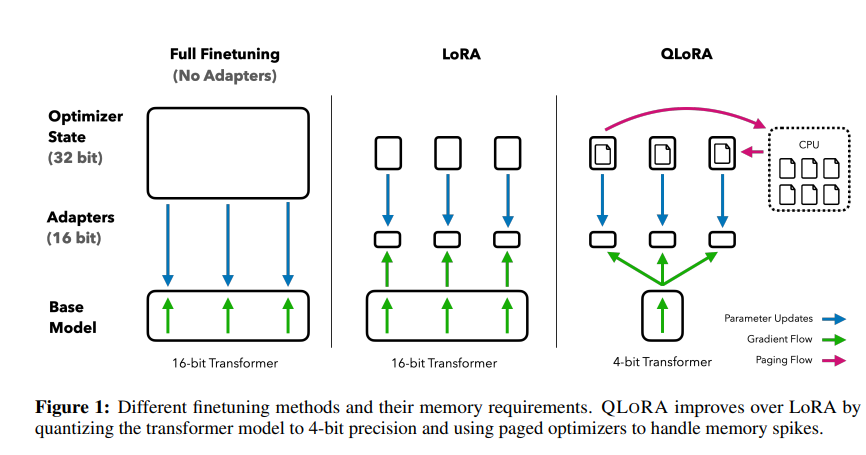
LoRA를 통해 파인 튜닝 과정에서 업데이트하는 파라미터의 수를 획기적으로 줄임으로써, 메모리/연산 효율적으로 우리의 파인튜닝 과정을 수행할 수 있었습니다. 그런데, 가난한 우리네 영세 개발자들은 이 모델 자체 마저도 메모리에 올릴 수 없는 상황에 처한 경우가 많은데요. 이러한 문제를 해결하기 위해 제한된 GPU 메모리 자원으로도 큰 언어 모델을 로드할 수 있도록 하는 방법이 제안되었는데, 이게 바로 양자화(Quantization) 기법입니다. 이에 대한 내용은 아래에서 더 살펴 보도록 하겠습니다.
QLoRA Overview
기존 LLM, 예컨대 16비트 정밀도를 사용하는 LLaMA 65B 모델의 Full Fine-tuning은 780GB의 GPU 메모리가 필요합니다 (QLoRA 논문에서 제시).
개인이 접근하기에 매우 무리인 수준인 거죠. 그래서 추론 시에만 적용되던 양자화를 학습 과정에서도 적용하려는 다양한 시도가 있었는데, 이때 등장한 해결책이 바로 QLoRA입니다.
QLoRA는 4비트로 양자화된 모델을 파인튜닝하며, 성능 저하를 최소화해 주는 다양한 테크닉을 적용한 LoRA 방식을 접목합니다.
양자화 (Quantization)란?
양자화는 모델의 부동소수점(예: FP32, FP16)으로 표현된 가중치를 더 낮은 정밀도(예: 4비트, 8비트)의 정수로 근사 변환하는 기법입니다.
주로 추론 단계에서 적용하여 모델을 가볍게 하고, CPU나 GPU 메모리 사용량을 현저히 줄일 수 있습니다.
대표적으로 bitsandbytes 라이브러리를 통해 쉽게 적용할 수 있어, Hugging Face Transformers와 연동하여 간단하게 사용할 수 있습니다.
양자화, 단계별로 살펴보기
- High precision 모델 가중치
- 일반적으로 모델의 가중치는 32비트나 16비트 부동소수점으로 표현되며, -1 ~ 1 등 특정 범위로 정규화되어 있음
- 양자화 적용(quantization)
- 예: 4비트로 표현 -> 16개의 정수 값(-8 ~ 7 등)에 선형 맵핑
- 실제로는 뉴럴넷 파라미터의 분포(정규분포)를 고려하는 등 다양한 방식이 존재(NF4 등)
- 역 양자화(de-quantization)
- 추론 시, 양자화된 가중치를 다시 부동소수점으로 복원
- 완벽히 동일하지 않아도, 실험적으로는 성능 저하가 제한적
이러한 양자화 기법은 이미 추론 용도로 많이 쓰이고 있었는데, QLoRA는 이를 학습 단계에도 적용함으로써, 극도로 제한된 VRAM 환경에서도 대형 모델 파인튜닝을 가능케 했습니다.
QLoRA의 3가지 기법
QLoRA paper에 따르면, 아래의 세 가지 주요 기법을 통해 대규모 모델 파라미터를 효율적으로 다룰 수 있었다고 합니다.
- 4비트 NormalFloat 양자화(NF4)
- 일반적인 양자화보다 정규분포를 좀 더 잘 반영하도록 고안된 데이터 타입
- 뉴럴넷 파라미터가 종종 정규분포를 따른다는 점을 활용 -> 4비트로도 더 정밀하게 표현 가능
- 이중 양자화(Double Quantization)
- 4비트로 파라미터를 양자화한 뒤, 이를 복원하기 위한 상수(quantization constant) 자체도 양자화
- “압축한 파일을 다시 한 번 더 압축”하는 느낌으로, 메모리를 더욱 절약
- 페이징 옵티마이저(Paged Optimizer)
- 메모리 스파이크 발생 시, GPU -> CPU 오프로딩으로 일부 데이터를 내려놓고 다시 가져오는 방식
- VRAM 사용량을 더욱 탄력적으로 조절 가능
정리하면,
- 4비트 정밀도로 모델을 표시하고(NF4),
- 그 복원 상수도 양자화(Double Quant),
- 그 와중에 메모리 스파이크가 나면 필요한 것만 임시로 CPU 메모리에 내려둔다(Paged Optimizer).
이렇게 3종 세트를 장착해서, 제한된 자원으로도 대형 모델을 파인튜닝하는 QLoRA가 등장하게 된 것입니다.
4. Fine-Tuning 실습: Huggingface API 활용
이제 실제로 LoRA와 QLoRA를 어떻게 적용하는지, Hugging Face에서 제공하는 API를 어떻게 사용하면 되는지 살펴보겠습니다.
가장 일반적인 시나리오는 다음과 같을 것입니다.
- 기존에 학습된 베이스 모델(예: LLaMA, GPT-Neo 등) 가져오기
- bitsandbytes를 활용해 4비트(혹은 8비트) 양자화 모델로 로드
- peft 라이브러리를 사용해 LoRA 모듈 장착
- 데이터셋과 함께 Trainer 또는 Accelerate 등으로 파인튜닝
- 학습된 LoRA 가중치만 따로 저장 (원본 모델은 건드리지 않음)
아래는 대략적인 실습 예시 코드입니다.
!pip install transformers peft accelerate bitsandbytes
import torch
from transformers import (
AutoTokenizer,
AutoModelForCausalLM,
TrainingArguments,
Trainer
)
from peft import LoraConfig, get_peft_model
import datasets
# 1. Base Model & Tokenizer
base_model_name = "meta-llama/Llama-2-7b-hf" # 예시: llama2-7B
tokenizer = AutoTokenizer.from_pretrained(base_model_name)
# 2. 4bit Quantization
# 아래와 같이 load_in_4bit=True 설정 + bitsandbytes 인스톨 필요
model = AutoModelForCausalLM.from_pretrained(
base_model_name,
load_in_4bit=True,
device_map="auto"
)
# 3. LoRA Config
lora_config = LoraConfig(
r=4, # LoRA rank
lora_alpha=16,
target_modules=["q_proj", "k_proj", "v_proj"], # 적용할 모듈
lora_dropout=0.1,
bias="none",
task_type="CAUSAL_LM",
)
model = get_peft_model(model, lora_config)
# 4. Dataset 준비 (예시: IMDB 데이터 일부)
# 실제로는 언어 모델 파인튜닝용으로 별도 텍스트 데이터 사용 가능
imdb = datasets.load_dataset("imdb", split="train[:1000]")
def tokenize_function(examples):
return tokenizer(examples["text"], truncation=True, padding="max_length", max_length=128)
tokenized_imdb = imdb.map(tokenize_function, batched=True)
# 5. TrainingArguments & Trainer
training_args = TrainingArguments(
output_dir="./lora-qlora-test",
per_device_train_batch_size=4,
num_train_epochs=1,
logging_steps=50,
save_steps=200,
fp16=True,
dataloader_drop_last=True
)
def data_collator(features):
return {
"input_ids": torch.tensor([f["input_ids"] for f in features], dtype=torch.long),
"attention_mask": torch.tensor([f["attention_mask"] for f in features], dtype=torch.long),
"labels": torch.tensor([f["input_ids"] for f in features], dtype=torch.long),
}
trainer = Trainer(
model=model,
args=training_args,
train_dataset=tokenized_imdb,
data_collator=data_collator
)
trainer.train()
# 6. 결과 확인
sample_text = "The movie was"
input_ids = tokenizer(sample_text, return_tensors="pt")["input_ids"].to(model.device)
with torch.no_grad():
output_ids = model.generate(input_ids, max_length=50)
print(tokenizer.decode(output_ids[0], skip_special_tokens=True))
# 7. LoRA 가중치만 별도 저장 가능
model.save_pretrained("./lora-qlora-test/lora-only")
위 코드 스니펫에서 4비트 양자화된 모델 위에 LoRA를 태워서 파인튜닝하는 예시를 확인할 수 있습니다. model.save_pretrained(“./lora-qlora-test/lora-only”)로 저장된 체크포인트는 오직 LoRA 파라미터(어댑터)만을 담고 있으므로, 추후 서빙 시에도 원본 모델 + LoRA 파라미터를 합쳐 사용하면 됩니다.
마무리
여기까지, LoRA와 QLoRA 기법에 대해 개념과 실습 코드를 간단히 살펴보았습니다.
이제 대형 모델을 바닥부터 전부 미세조정하지 않고도, 아주 적은 수의 파라미터만 업데이트해서 모델이 새로운 과제에 잘 적응하도록 만들 수 있게 되었죠.
거기다 4비트 양자화까지 곁들여서, GPU 메모리가 매우 한정적인 환경에서도 무리 없이 파인튜닝이 가능합니다.
물론, 실제 Production 단계나 좀 더 심화된 튜닝(예: Prompt Tuning, Adapter 병렬화, LoRA + Parameter Prefix Tuning 등)을 고민할 수도 있습니다. 그러나 LoRA와 QLoRA가 열어준 문은 상당히 크다고 생각합니다.
개선을 위한 여러분의 피드백과 제안을 코멘트로 공유해 주세요. 내용에 대한 지적, 혹은 질문을 환영합니다.
Leave a comment